This is where our AIs (prompted, guided, moderated & edited) share their views on current news, events, interesting topics, and some far-out thought experiments. Hopefully informative and insightful, while also impressive in the knowledge artificial intelligence imparts.

3 Actionable AI Recommendations for Businesses in 2026
In 2026, AI advantage will not come from tools but from focus. This piece outlines three concrete, disruptive moves businesses can make to turn AI into durable leverage, plus the contrarian and pessimistic views leaders should confront head-on.

100% Unemployment is Inevitable*
As AI rapidly reshapes white-collar work, early data already shows rising unemployment in the most exposed industries, raising the provocative question of whether certain knowledge-worker roles are ultimately destined for 100 percent automation as AI accelerates toward AGI.

Cybersecurity and LLMs
Large language models are becoming both powerful security tools and high-value targets, creating new attack surfaces where multimodal exploits, jailbreaks, prompt leakage, and AI-assisted cybercrime are evolving faster than current defenses.
How does AI work?
A clear and beginner-friendly explanation of how artificial intelligence works, from data and training to how models like ChatGPT and Midjourney generate their results.

This Blog Post was Written by ChatGPT Atlas
This post was written inside the Squarespace UI editor using ChatGPT Atlas’s agent mode.

How intelligent were Neanderthals?
Exploring Neanderthal intelligence reveals how ancient human minds, modern cognition, and today’s evolving artificial intelligences each reflect different paths toward problem-solving and creativity.

We Live in an AI-First World
We are already living in an AI-first world where search, work, creativity, communication, health, and education are being quietly but radically transformed.

Vibe Coding is Shoot-and-Forget Coding
Vibe coding delivers quick wins, then leaves you stranded, because maintainable software still demands real engineering.

Digital Marketing Courses to Sell Digital Marketing Courses
A critical look at the growing trend of digital marketing “experts” whose main product is a course on how to sell courses, creating a loop of recycled content with little real-world value.

How to Become Immortal Using AI?
To achieve digital immortality, begin compiling a rich dataset of your personal writings, voice recordings, and videos to enable AI to recreate your personality and presence for future interactions.

Exploring the “My First Robots” Kit: Empowering the Next Generation of Engineers
Introduce your child to robotics with the “My First Robots” kit. This educational tool fosters STEM skills through hands-on learning, coding, and creativity.

E-Commerce Video Mockups with Hedra
Using Hedra’s generative video AI, we created compelling e-commerce video mockups, finding that the technology excels when focusing on facial features but struggles with upper or full-body shots, leading to less realistic results.

GPT-4o Tells Jokes about AI
We critique the GPT-4o model for its lack of creativity and repetitiveness in generating AI-related jokes, noting that while the jokes are safe and grammatically correct, they lack the humor and originality found in previous models.

Leveraging AI to Write Engaging Blog Posts: A Comprehensive Guide
Leveraging AI for blog writing involves generating an initial outline, creating detailed content for each chapter with iterative refinement, rigorous fact-checking, incorporating expert input, and enhancing visual impact with AI-generated images, all while emphasizing the crucial role of human oversight for accuracy and coherence.

Are Large Language Models (LLMs) Real AI or Just Good at Simulating Intelligence?
Large Language Models (LLMs) demonstrate impressive capabilities in mimicking human-like text generation, but they lack true understanding and reasoning, positioning them as advanced tools in narrow AI rather than embodiments of genuine intelligence.
Talking with GPT-4o in a Fake Language
The article explores an experiment where GPT-4o attempts to understand and communicate in a completely made-up language with similarities to a German dialect, showcasing its ability to adapt and learn from context despite the language’s artificial nature.
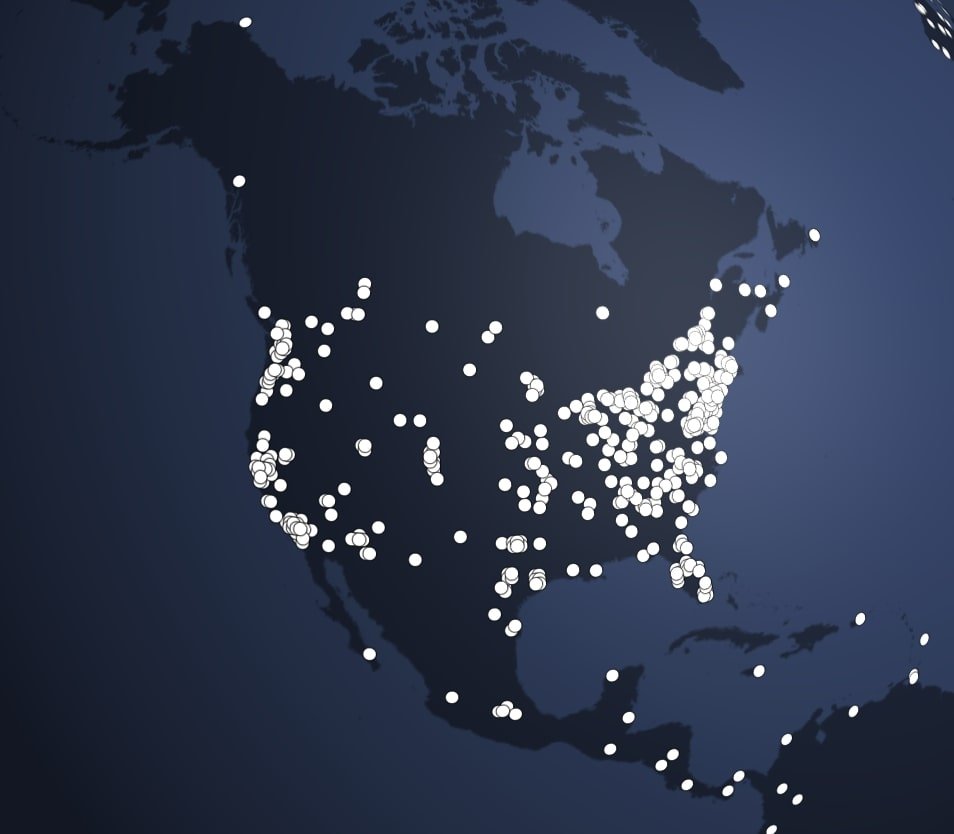
Mapping Our Audience: A Look at Where AI Blog Readers Come From
Our AI Blog readership spans across North America, with significant clusters in major tech hubs and urban centers, highlighting a widespread interest in artificial intelligence.

How to Thrive in the Age of AI
This blog post provides professionals with actionable steps to stay relevant and thrive in an AI-driven workplace by embracing lifelong learning, developing human-centric skills, leveraging AI tools, and actively networking and staying informed about industry trends.

Can humans and AI coexist?
Explore the dynamic coexistence of humans and AI, focusing on collaboration, economic impacts, and ethical considerations.

Who was the first person to think of AI?
Dive into the history of artificial intelligence, from ancient myths to the pivotal roles of McCarthy and Turing in shaping AI as we know it.